همه چیز برای شروع Apache Lucene
معرفی
Apache Lucene یک پروژه متنباز به زبان جاوا است که امکان افزودن قابلیت جستجو به برنامه های کاربردی را با مکانیزمی کارا و آسان فراهم میآورد . به زبانی دیگر Lucene مجموعهای از کتابخانههای کاربردی و مفید است که میتوان از آن در توسعه هر نوع برنامهای که میخواهید قابلیت جستجو داشته باشد، استفاده کرد. این نوشتار به بررسی برخی از کلاسهای این کتابخانه و همچنین عملکرد کلی آنها میپردازد و میتواند شروع خوبی برای استفاده از این کتابخانه باشد.
اینکه کاربران بخواهند لیستی از سندها را با مد نظر گرفتن شرایط خاصی بازیابی کنند یک نیاز معمول و پرکاربرد است. برای نمونه یک کاربر میخواهد سندهایی را که بوسیله نویسنده خاصی نوشته شده است یا اینکه سندهایی که در عنوان آنها کلمه یا عبارت خاصی موجود است را بازیابی کند. چنین درخواستهایی بوسیله پایگاه دادههای آشنایی که میشناسیم بسادگی قابل پاسخ دادن هستند. برای نمونه اگر جدولی داشته باشیم که اطلاعات عنوان، نام نویسنده و نام ناشر را داشته باشد میتوان پرسوجوهای یادشده را مدیریت کرد. اکنون تصور کنید کاربر سندهایی را میخواهد که در محتوای آنها عبارت یا واژهی خاصی تکرار شده باشد. چنین درخواست هایی حتی اگر محتوای اسناد را داخل پایگاه داده داشته باشید زمان بسیار زیادی را میخواهد. به همین دلیل سازوکاری نیاز است که همه واژههای یک سند را بررسی و با اعمال کردن قاعدههایی روی آنها جستجو و در نتیجه زندگی را برای ما آسان کند.
Lucene چگونه کار میکند؟
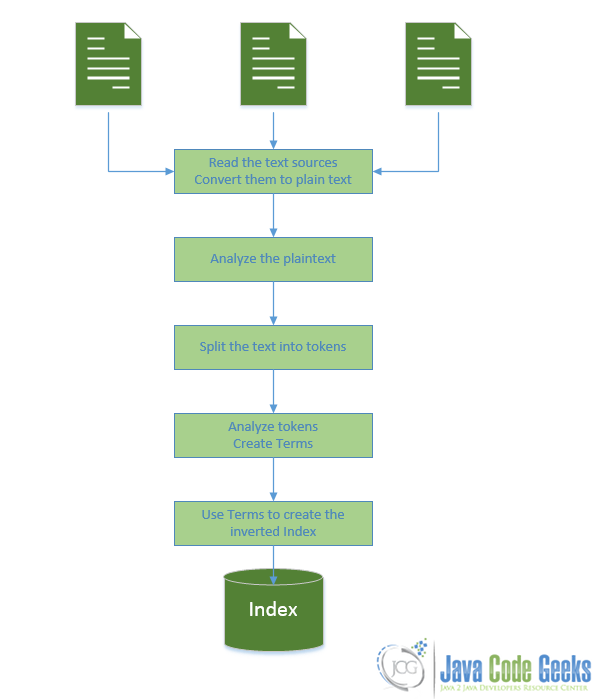
Lucene جستجوی سریع خود را با استفاده از ایندکسها به نتیجه میرساند و به جای استفاده از ایندکسهای کلاسیک که در آن هر سند شامل لیست کاملی از واژههایی است که در آن وجود دارند از ایندکسهای وارونه استفاده میکند.بدین گونه که برای هر واژه لیستی از سندها را فراهم میآورد که آن واژه در آنها وجود دارد. همچنین مکان یا مکانهایی که هر واژه در سند تکرار شده است را نیز در لیست اعمال میکند. برای نمونه در شکل زیر واژه lucene در سند اول و در مکان ششم آن وجود دارد، همچنین در سند دوم و مکان چهارم ان .
Lucene -> { (1,6), (2,4) } full -> { (1,10),(2,9) } going -> { (1,0) } index -> { (3,3) } search -> { (1,11), (2,10)}
:در لینوکسDirectory directory = FSDirectory.open( new File("/home/milad/lucene/index"));
:در ویندوزDirectory directory = FSDirectory.open( new File("C:/Users/Milad/Index"));
Document doc = new Document();
۳- فیلدها
به هر سند میتوان مجموعهای از فیلدها اضافه کرد که هر کدام میتوانند اطلاعاتی را درباره سند ارائه دهند. برای مثال یک فیلد میتواند عنوان، شناسه سند، توصیفی دربارهی سند یا محتوای آن باشد. هر فیلد میتواند شامل سه مشخصه باشد: نام، نوع و مقدار. نام و مقدار که نیازی به توضیح ندارند اما نوع فیلد نمایانگر رفتار سند میباشد. برای مثال میتوانید نوع فیلد را بهگونهای تنطیم کنید که روی ذخیرهشدن، ایندکسشدن یا تجزیه شدن اجزای یک مقدار کنترل داشته باشید.
در قطعه کد بالا یک شی Document ساختهایم و فیلدی را با مقداری مشخص شده از نوع رشته به آن اضافه کردهایم همچنین فیلد را بهگونهای پیکربندی کردهایم که ذخیره شود و در نتیجه طی عمل جستجو بازیابی شود.
Directory indexDirectory = FSDirectory.open( new File("/home/milad/workspace/lucene/index"));
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
IndexWriter indexWriter = new IndexWriter(indexDirectory,config);indexWriter.addDocument(doc);
شکل زیر نیز کارهایی را که در مرحله ایندکس کردن رخ میدهد به زیبایی نشان میدهد.
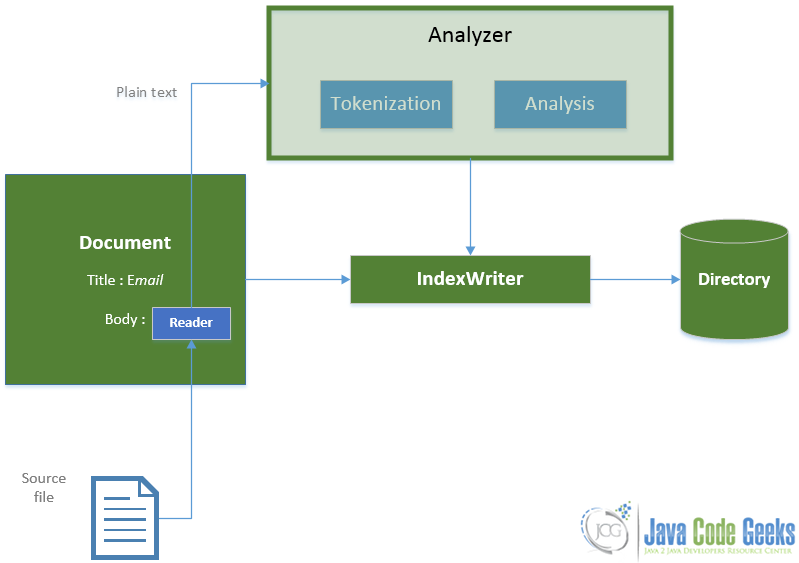
اجزا اصلی برای عملیات جستجو
۱- QueryBuilder و Query
پس از اینکه ایندکسها ساخته شد نوبت به انجام جستجو روی دادههای ایندکسشده است. نکته مهمی که در اینجا باید مورد توجه قرار گیرد این است که در پیادهسازی عملیات جستجو باید از همان نوع آنالیزوری استفاده کنید که در مرحله ایندکسکردن اسناد استفاده شده بود. کلاس Query یک کلاس انتزاعی است و برای ساخت نمونهای از آن ابتدا باید نمونهای از کلاس QueryBuilder ایجاد کرد و با استفاده از آن، یکی از انواع زیرکلاسهای Query را به شیای از کلاس Query مقید کرد. یکی از زیرکلاسهایQuery، کلاس BooleanQuery است که با استفاده از آن میتوان جستجوی بولی انجام داد. کلاسهای دیگری مانند WildcardQuery و PhraseQuery و … هم وجود دارند که متناسب با نامشان جستجو را انجام میدهند.
Analyzer analyzer = new StandardAnalyzer();
QueryBuilder builder = new QueryBuilder(analyzer);
Query query = builder.createBooleanQuery("content", queryStr);
۲- IndexReader
برای اینکه بخواهیم جستجویی روی ایندکسها انجام دهیم ابتدا باید بتوانیم به آنها دسترسی داشته باشیم. کلاس انتزاعی IndexReader این کار را انجام میدهد.
Directory directory = FSDirectory.open( new File("/home/milad/workspace/lucene/index"); I
indexReader indexReader = DirectoryReader.open(directory);۳- IndexSearcher
IndexSearcher searcher = new IndexSearcher(indexReader);
Query query = builder.createBooleanQuery("content", queryStr);
TopDocs topDocs =searcher.search(query, maxHits);با استفاده از متد (public TopDocs search(Query query, int n از کلاس IndexSearcher میتوان عمل جستجو را انجام داد. این متد دو آرگومان ورودی میگیرد اولی پرسوجوی ماست و دومی حد بالای نتایج بازگشتی را مشخص میکند. متد در نهایت نمونهای از کلاس TopDocs را برمیگرداند که شامل اسنادی است که پاسخ پرسوجوی ما هستند. TopDocs فیلدی بنام []ScoreDoc دارد که خود کلاسی است شامل دو فیلد doc و score، اولی شناسه سند بازیابی شده و دومی رتبه سند میباشد.
یک مثال ساده از توضیحات بالا
با بررسی دو کلاس زیر میتوانید مفاهیم گفتهشده در بالا را بهتر درک نمایید.
کلاس SimpleIndexer.java
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.nio.file.Path;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.StoredField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.FSDirectory;
public class SimpleIndexer {
private static final Path dirToBeIndexed = Paths.get("/home/milad/workspace/lucene/sourcefiles");
private static final Path indexDirectory = Paths.get("/home/milad/workspace/lucene/index");
public static void main(String[] args) throws Exception {
SimpleIndexer indexer = new SimpleIndexer();
int numIndexed = indexer.index(indexDirectory, dirToBeIndexed);
System.out.println("Total files indexed " + numIndexed);
}
private int index(Path indexdirectory, Path dirtobeindexed) throws IOException {
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
IndexWriter indexWriter = new IndexWriter(FSDirectory.open(indexDirectory),config);
File[] files = dirtobeindexed.toFile().listFiles();
for (File f : files) {
System.out.println("Indexing file " + f.getCanonicalPath());
Document doc = new Document();
doc.add(new TextField("content", new FileReader(f)));
doc.add(new StoredField("fileName", f.getCanonicalPath()));
indexWriter.addDocument(doc);
}
int numIndexed = indexWriter.maxDoc();
indexWriter.close();
return numIndexed;
}
}
کلاس SimpleSearcher.java
import java.nio.file.Path;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.QueryBuilder;
public class SimpleSearcher {
private static final Path indexDirectory = Paths.get("/home/milad/workspace/lucene/index");
private static final String queryString = "Hello fun";
private static final int maxHits = 100;
public static void main(String[] args) throws Exception {
SimpleSearcher searcher = new SimpleSearcher();
searcher.searchIndex(indexDirectory, queryString);
}
private void searchIndex(Path indexdirectory2, String queryStr)
throws Exception {
Directory directory = FSDirectory.open(indexdirectory2);
IndexReader indexReader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(indexReader);
Analyzer analyzer = new StandardAnalyzer();
QueryBuilder builder = new QueryBuilder(analyzer);
Query query = builder.createBooleanQuery("content", queryStr);
TopDocs topDocs =searcher.search(query, maxHits);
ScoreDoc[] hits = topDocs.scoreDocs;
for (int i = 0; i < hits.length; i++) {
int docId = hits[i].doc;
Document d = searcher.doc(docId);
System.out.println(d.get("fileName") + " Score :"+hits[i].score);
}
System.out.println("Found " + hits.length);
}
}
import java.nio.file.Path;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.QueryBuilder;
public class SimpleSearcher {
private static final Path indexDirectory = Paths.get("/home/milad/workspace/lucene/index");
private static final String queryString = "Hello fun";
private static final int maxHits = 100;
public static void main(String[] args) throws Exception {
SimpleSearcher searcher = new SimpleSearcher();
searcher.searchIndex(indexDirectory, queryString);
}
private void searchIndex(Path indexdirectory2, String queryStr)
throws Exception {
Directory directory = FSDirectory.open(indexdirectory2);
IndexReader indexReader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(indexReader);
Analyzer analyzer = new StandardAnalyzer();
QueryBuilder builder = new QueryBuilder(analyzer);
Query query = builder.createBooleanQuery("content", queryStr);
TopDocs topDocs =searcher.search(query, maxHits);
ScoreDoc[] hits = topDocs.scoreDocs;
for (int i = 0; i < hits.length; i++) {
int docId = hits[i].doc;
Document d = searcher.doc(docId);
System.out.println(d.get("fileName") + " Score :"+hits[i].score);
}
System.out.println("Found " + hits.length);
}
}
پیوست 1: نحوه دانلود و استفاده از کتابخانه lucene
برای شروع میتوانید کتابخانه را از این لینک دانلود کنید. لینک شامل کدهایی جاوایی lucene است. اگر میخواهید از زبانهای برنامهنویسی دیگر استفاده کنید می توانید از لینکهای زیر استفاده کنید:
- CLucene: پیادهسازی آن به زبان سیپلاسپلاس
- Lucene.Net: برای استفاده در زبانهای داتنتی
- PyLucene: پیادهسازی پایتونی
اگر کتابخانه Lucene به زبان جاوا را دانلود کنید و آن را از حالت فشرده خارج کنید پوشهای بنام core وجود دارد که هسته اصلی کتابخانه در آن قرار دارد برای اضافه کردن هسته کتابخانه به eclipse میتوانید مراحل زیر را انجام دهید:
- روی نام پروژه خود کلیک راست کنید در منوی ظاهر شده مسیر Build Path --> Configure Build Path را دنبال کنید.
- در پنچره باز شده تب libraries را انتخاب و روی دکمه Add External JARs کلیلک کنید سپس مسیری را که فایل lucene-core-6.3.0.jar در آن قرار دارد را پیدا و فایل یادشده را به پروژه اضافه نمایید.
پیوست ۲: لینکهای مفید دیگر
- آموزش lucene در سایت tutorialspoint
- دانلود کتاب Lucene in action
- منبع اصلی نوشته
- سایتی مفید
- ویدئویی در یوتیوب
لطفا:
اشکلات علمی و نگارشی را با نظر دادن اطلاعرسانی کنید.

